AWS Instance Backup Automation with Nectus
Having your data backed up and secured is crucial for business-critical systems. If your servers run in AWS infrastructure,
then you already have an advantage of performing backup of the hosted instances using Amazon built-in features.
This can be performed manually using AWS console the following way. First, select Instances menu from EC2 Dashboard.
Then select an instance you would like to backup.
In Description tab you will see the Block devices attached to the selected instance.
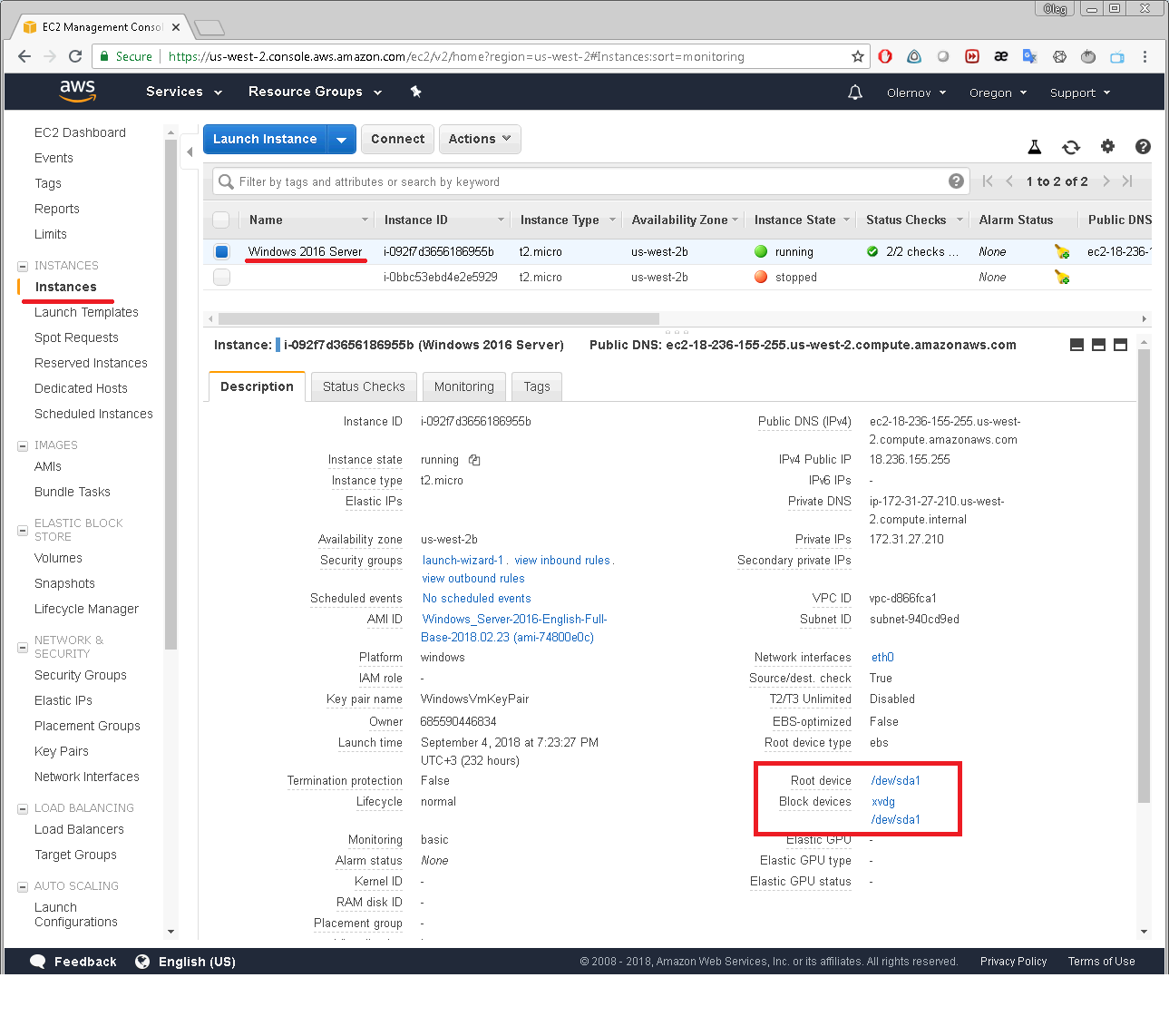
Clicking on one of the block devices will bring up the window displaying the block device’s EBS ID:
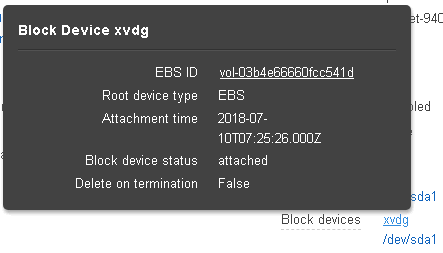
By clicking that EBS ID you get to the Volumes menu of the EC2 Dashboard:
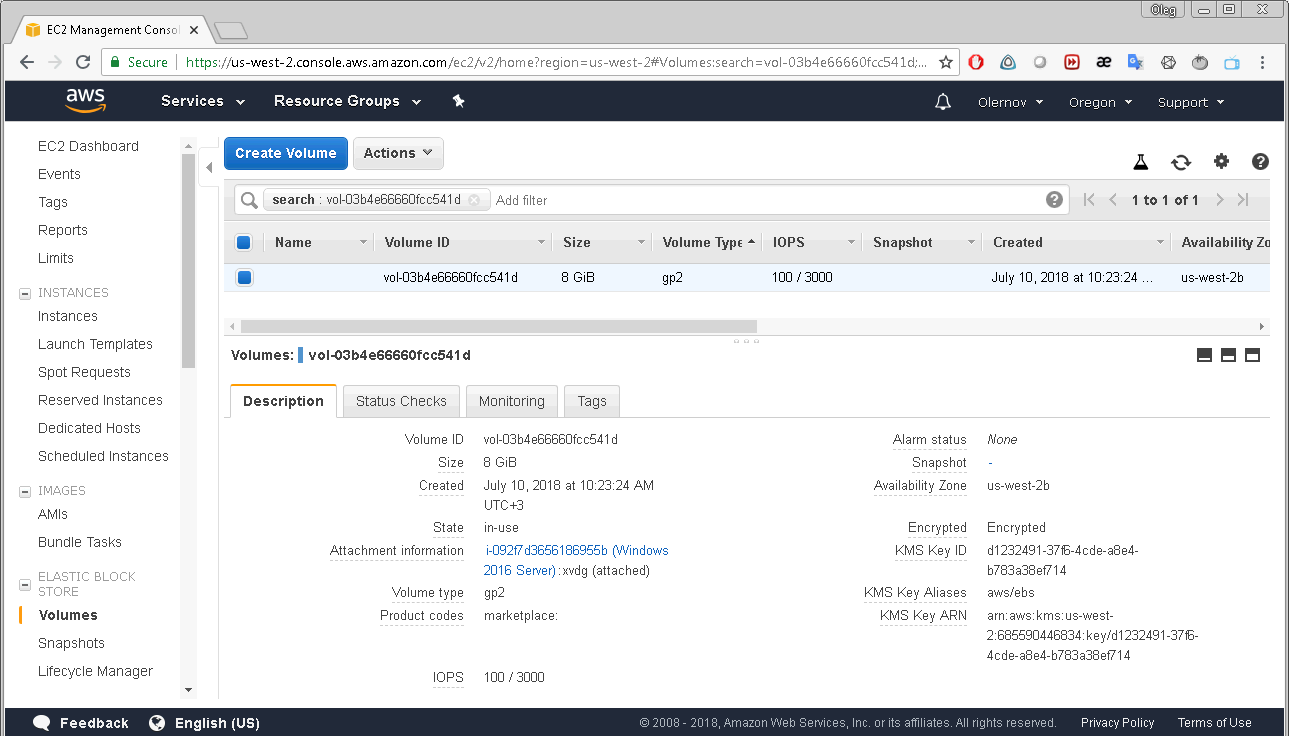
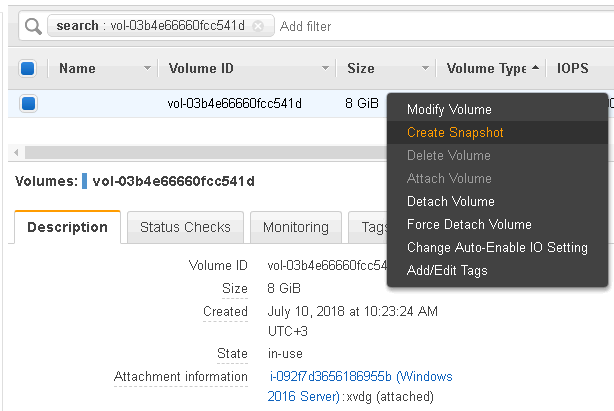
Right-click on the selected volume will display a menu with “Create snapshot” option.
After selecting this option you have to enter a description of your snapshot and the snapshot will be created.
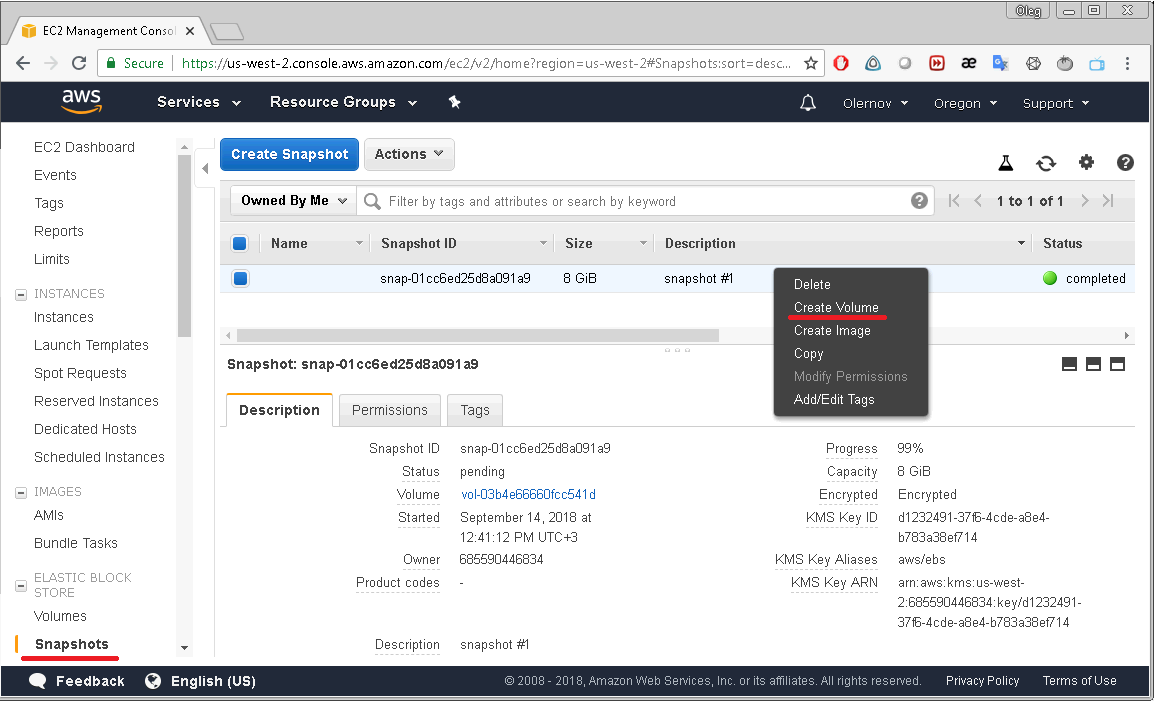
After that the snapshot created will appear on the list displayed on the EC2 Dashboard/Snapshots page. To restore data from that snapshot you should select
“Create Volume” option from the snapshot’s context-menu. A new volume will appear with exactly the same data you had on your volume when snapshot was created.
But taking snapshots manually is hardly an option, especially if you deal with a lot of the EC2 instances. This process must be automated.
One of possible solutions is utilizing the Nectus AWS backup functionality. Nectus is able to take snapshots of your volumes constantly and
regularly with the required periodicity according to the backup profiles you set.
The following steps will show how to enable and set up the automated backup of AWS instances using Nectus. First you need to set up your backup profiles.
Select Settings/General Settings/AWS Integration menu.
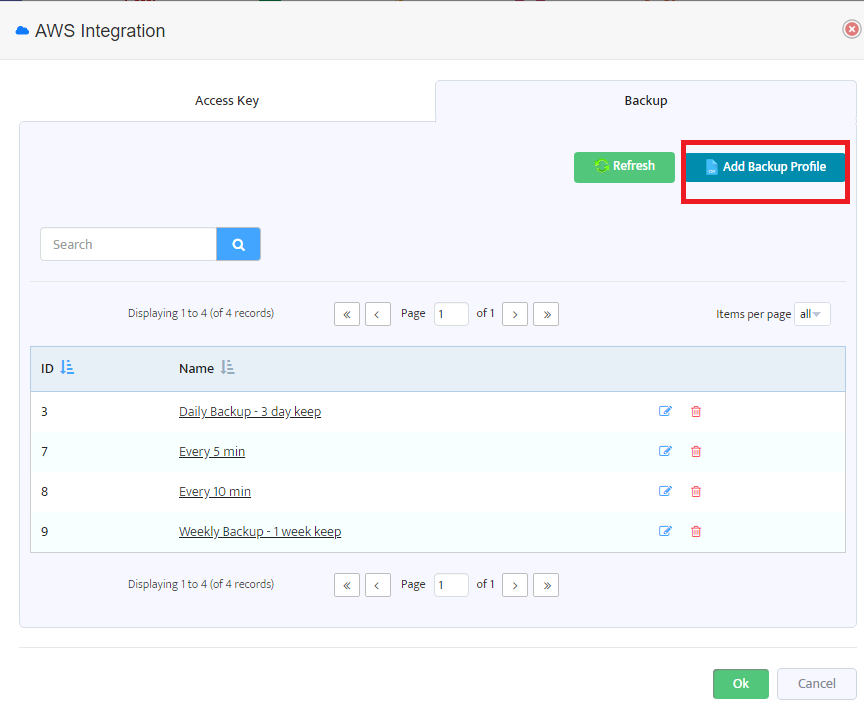
In the “Backup” tab you will see backup profiles already created and also the “Add Backup Profile” button.
Pressing this button will open the following “Add New AWS Backup Profile” dialog.
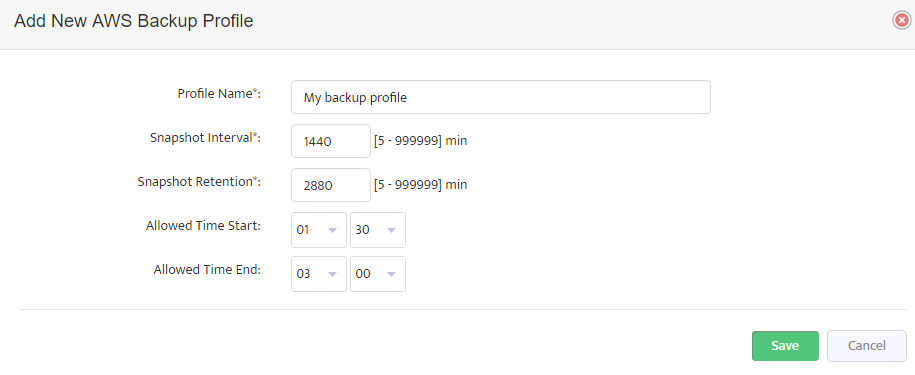
Here you can enter a name for a new backup profile, periodicity of snapshots creation (Snapshot Interval), period of retention for snapshots created (Snapshot retention)
and the allowed time interval to take snapshots (this setting is available only if Snapshot Interval is 1440 minutes or more).
Pressing “Save” button will add the new backup profile to the list. Editing of existing profiles is also possible.
You can create any number of backup profiles for different purposes.
For example, you may want to backup your most critical production instances quite often (every 5 minutes) but your test servers rarely (once a day or maybe even once a week).
The procedure of taking a snapshot is free of charge from Amazon but storing them is charged depending on the volume (see AWS EC2 pricing).
That should be considered when choosing the Snapshot retention period.
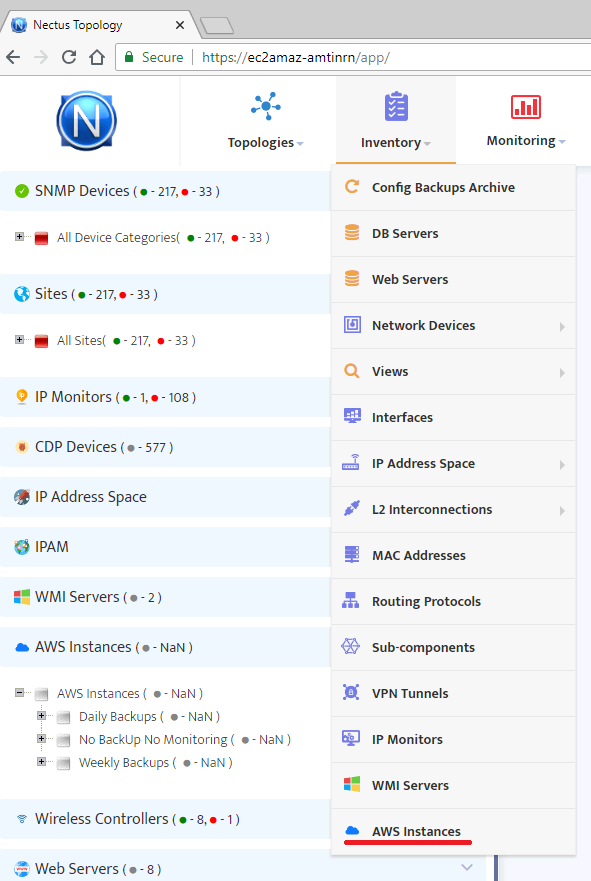
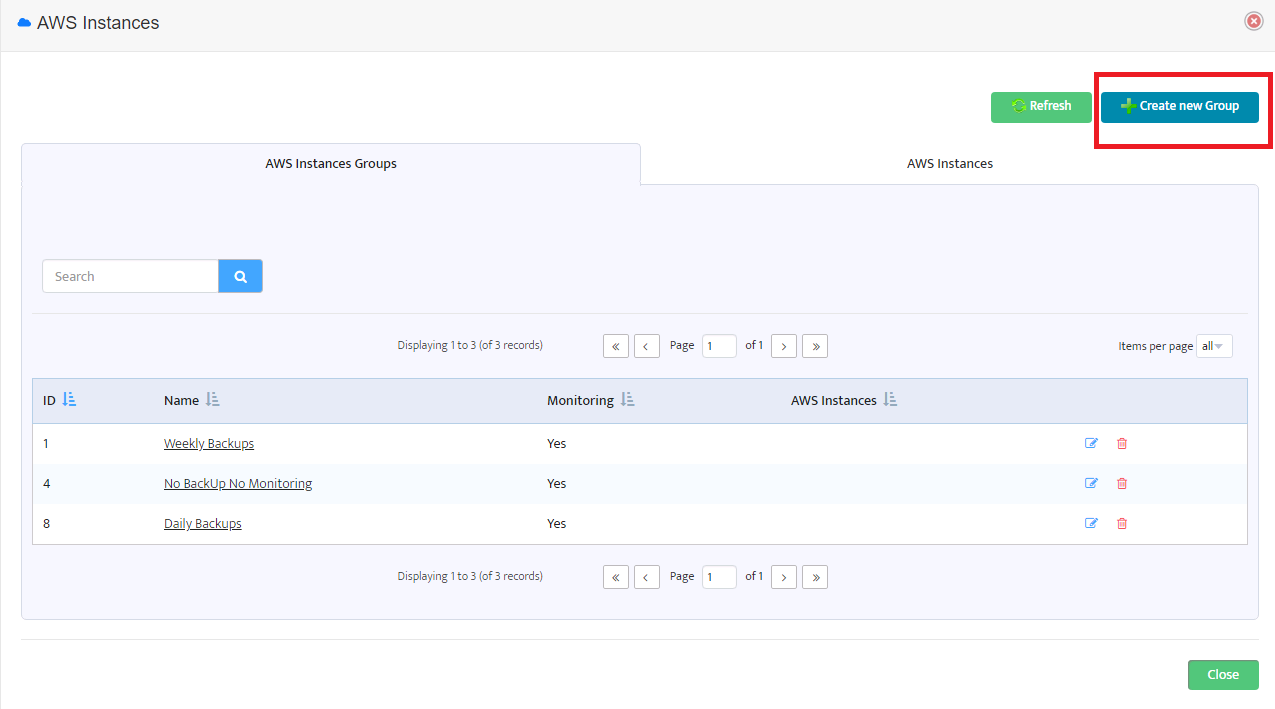
After you have set the required backup profiles, it is time to assign them to your instances. To perform it select “AWS Instances” from the “Inventory” menu.
In the form displayed you can see a list of already existing instance groups. To create a new AWS instance group press the button “Create new Group” at the top-right of the form.
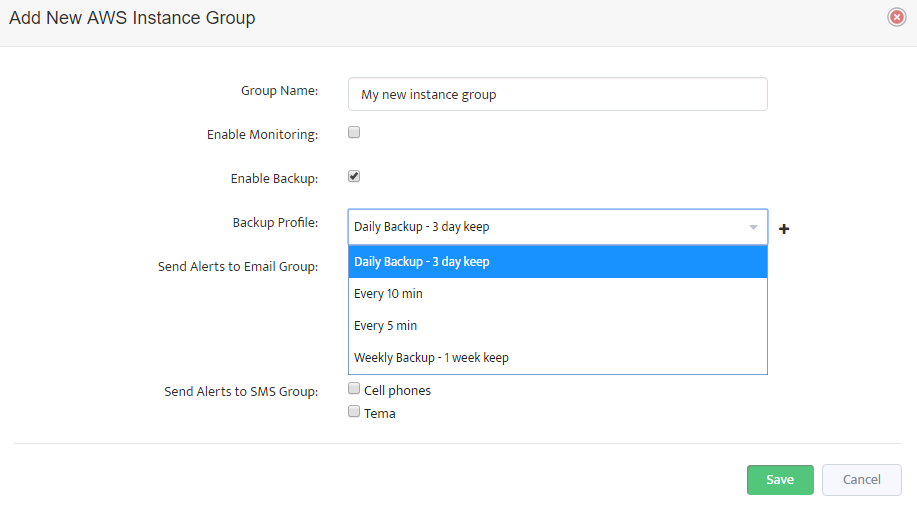
In the window opened you should set a new group name, check the “Enable Backup” box and choose one of the backup profiles created earlier.
If the box is not checked, then no backups will be performed for instances of this group.
Now when you have backup profiles assigned to AWS instance groups you can switch to the next tab “AWS Instances”.
The next window displays a list of AWS instances.
Each instance belongs to one of the AWS instance groups and so the group settings affect the instance backup policy.
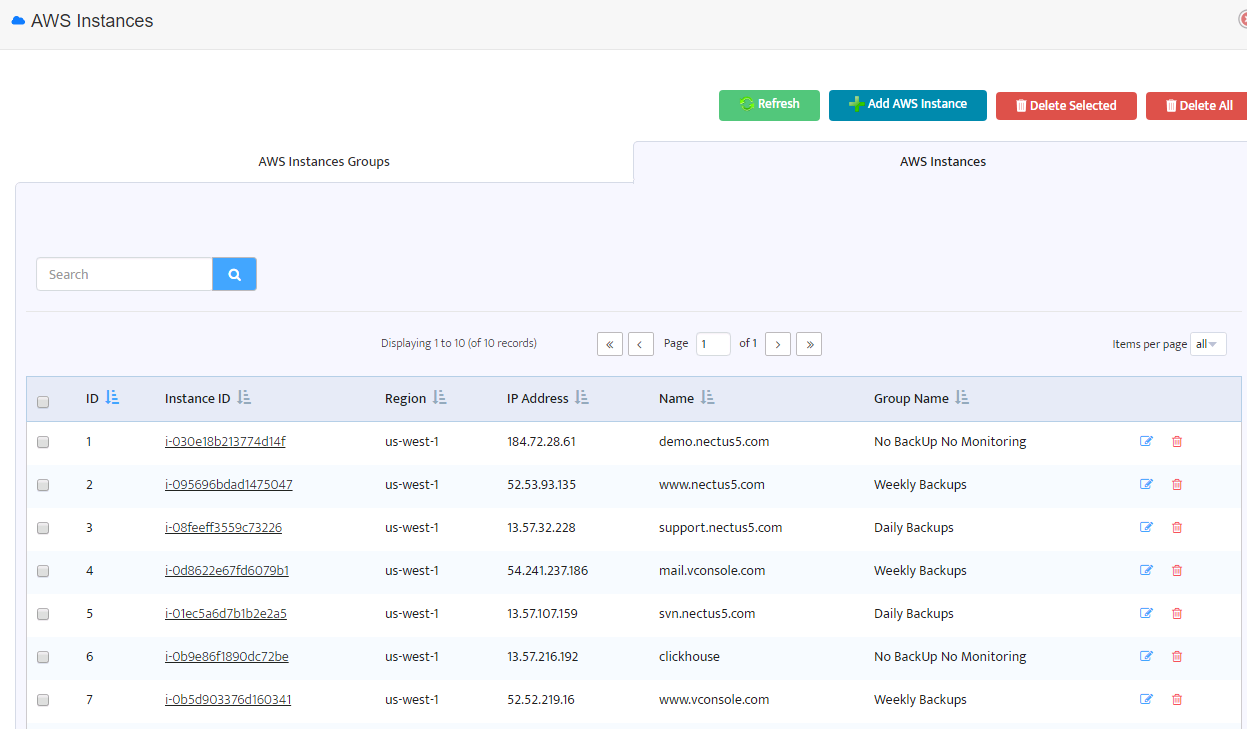
To change backup profile for an instance you should move it to another instance group with appropriate backup profile.
For example, if you want to change backup profile for “www.nectus5.com” from “Weekly Backups” to “Daily Backups”
just click on the Instance ID and change AWS instance group.
After such setup Nectus will automatically start creating new snapshots and deleting old ones.
You will see those snapshots in your EC2 Dashboard.